세 번째 HDBSCAN을 이용해서 클러스터링을 한다. 이 때 Clustering을 통해서 각 Document Vector에 대해서 유사한 Document끼리 묶어주는 과정을 진행한다.
그 다음에 C-TF-IDF를 통해서 각 묶어진 그룹(Topic 또는 Class)에 대해 해당 Topic을 잘 표현하는 단어를 찾는다.
마지막으로 Maximize Candidate Relevance Algorithm을 이용해서 적절히 Topic을 대표하는 Keyword들이 최대한 다양하게 선별되도록 조정한다. Document, Word Embedding Vector에 대해서 Cosine Similarity를 계산해서 Keyword List를 Return한다.
Official Document
C-TF-IDF
C-TF-IDF에서 C는 Class로, Class = Topic이다.
TF-IDF를 이용해서 각 Term 별로 가중치를 계산하는 방식은 동일하기 때문에 실제 code를 보더라도 sklearn 패키지의 TfidfTransformer를 그대로 상속해서 사용한다.
이름이 의미하는 것처럼 Class별로 Document를 묶어서 TF-IDF를 계산하는 방식이다.
Example
# BerTopic 설치
!pip install bertopic
from sklearn.datasets import fetch_20newsgroups
from bertopic import BERTopic
# 데이터셋 로드
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
# BERTopic Load, langeuage는 english로 했으나, multilingual로 설정 가능
# calculate_probabilities 옵션을 통해서 Documnent 별로 특정 Topic에 속하는 확류를 계산할수 있는데, 이게 문서 수가 100,000건이 넘어가면 꽤 느려짐
# 그런데 calculate_probabilities 옵션을 설정하지 않으면 visualize_probabilities를 사용할 수 있음
topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(docs)
# 생성된 토픽을 빈도순으로 볼 수 있는데 이 때 -1은 어떠한 Topic에 속하지 못한 Outlier이다.
freq = topic_model.get_topic_info(); freq.head(5)
# 0번토픽에 주로 등장하는 단어들을 볼 수 있다.
topic_model.get_topic(0) # Select the most frequent topic
# Visualization
# PLDAVIS와 비슷한 형태로 시각호를 지원해준다.
topic_model.visualize_topics()
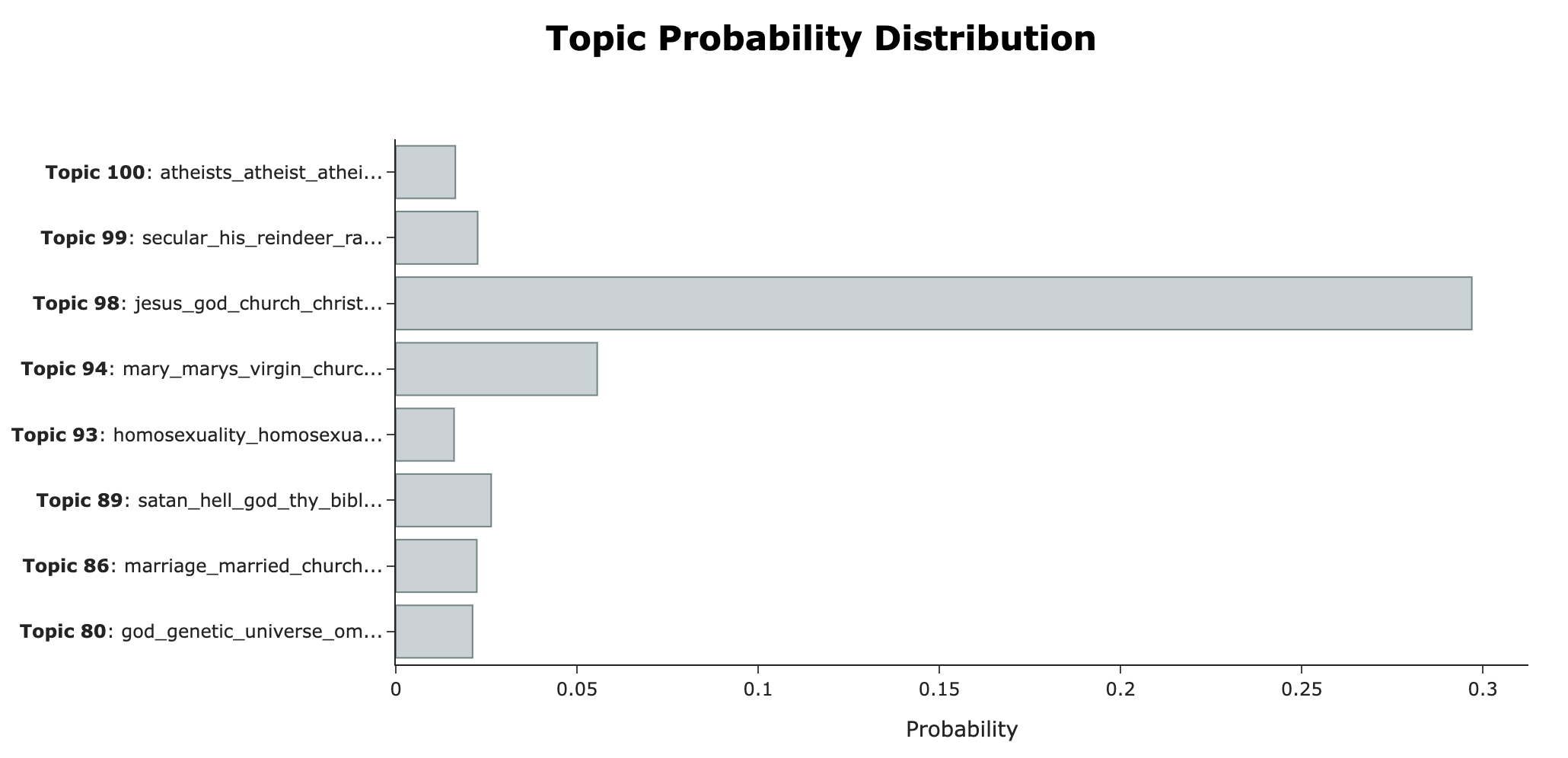
# 앞서 calculate_probabilities를 했다면 특정 Document에 대해서 Topic별 Probabilites를 확인할 수 있다.여기서 예시는 index 200번째 Document
topic_model.visualize_distribution(probs[200], min_probability=0.015)
# Topic 별 Hierarchy를 보여준다.
topic_model.visualize_hierarchy(top_n_topics=50)
# Topic을 대표하는 상위 단어 5개씩 보여준다.
topic_model.visualize_barchart(top_n_topics=5)
# Topic간 유사도를 Cosine Similarity로 계산후 Heatmap으로 표현
topic_model.visualize_heatmap(n_clusters=20, width=1000, height=1000)
# Topic내 대표하는 단어들에 대해서 c-tf-idf로 계산해서 각 단어가 Topic에서 차지하는 중요도를 계산했던 것을 Rank 순대로 보여준다.
topic_model.visualize_term_rank()
Embedding 방식이 다르다. Top2Vec은 Document Embedding과 Topic Modeling을 결합하였으나, BERTopic은 Topic Modeling을 분리해서 별도로 계산한다.
Logic이 미묘하게 다르다보니 Topic을 찾아나가는 방식도 다르다. Top2Vec은 Document Embedding 이후 HDBSCAN을 이용해서 차원상 밀집된 곳의 Centroid를 찾아서 Topic으로 설정한다. 하지만 BERTopic은 전체를 하나의 Cluster로 간주한 상황에서 Topic을 찾는 방식이다. Clustering을 기준에 두고 Topic Representation을 찾는 시점이 다르다.
그런데 이게 항상 어느 모델이 좋다고 이야기 하기 어려울 정도로, 방식이 다를 뿐 UMAP, HDBSCAN 외에 Technique으로는 Embedding만 다르고, 그외 추가로 제공하는 Function이 다소 다르다 보니 그 때 그 때 목적에 따라 사용하는 것이 좋다.






Member discussion