복잡한 다차원 확률 분포에서 직접 샘플링하는 것은 어려운 경우가 많습니다. 이러한 문제를 해결하기 위해 MCMC 방법이 등장했습니다.
고차원의 문제: 고차원 공간에서는 모든 가능한 값들을 커버하기 위해 필요한 샘플 수가 기하급수적으로 증가합니다. 이로 인해 효율적인 샘플링이 매우 어렵습니다.
비선형성: 다차원 확률 분포는 종종 비선형성을 띄며, 특정 변수들 간의 복잡한 상호작용이 존재합니다. 이러한 상호작용을 정확히 모델링하고 샘플링하기 위해서는 고도의 계산이 필요합니다.
복잡한 형태: 확률 분포가 복잡한 형태를 가질 경우, 이를 수학적으로 표현하고 샘플링하는 것이 어려울 수 있습니다. 예를 들어, 꼬리가 긴 분포나 여러 개의 모드를 가진 분포는 직접 샘플링하기 어렵습니다.
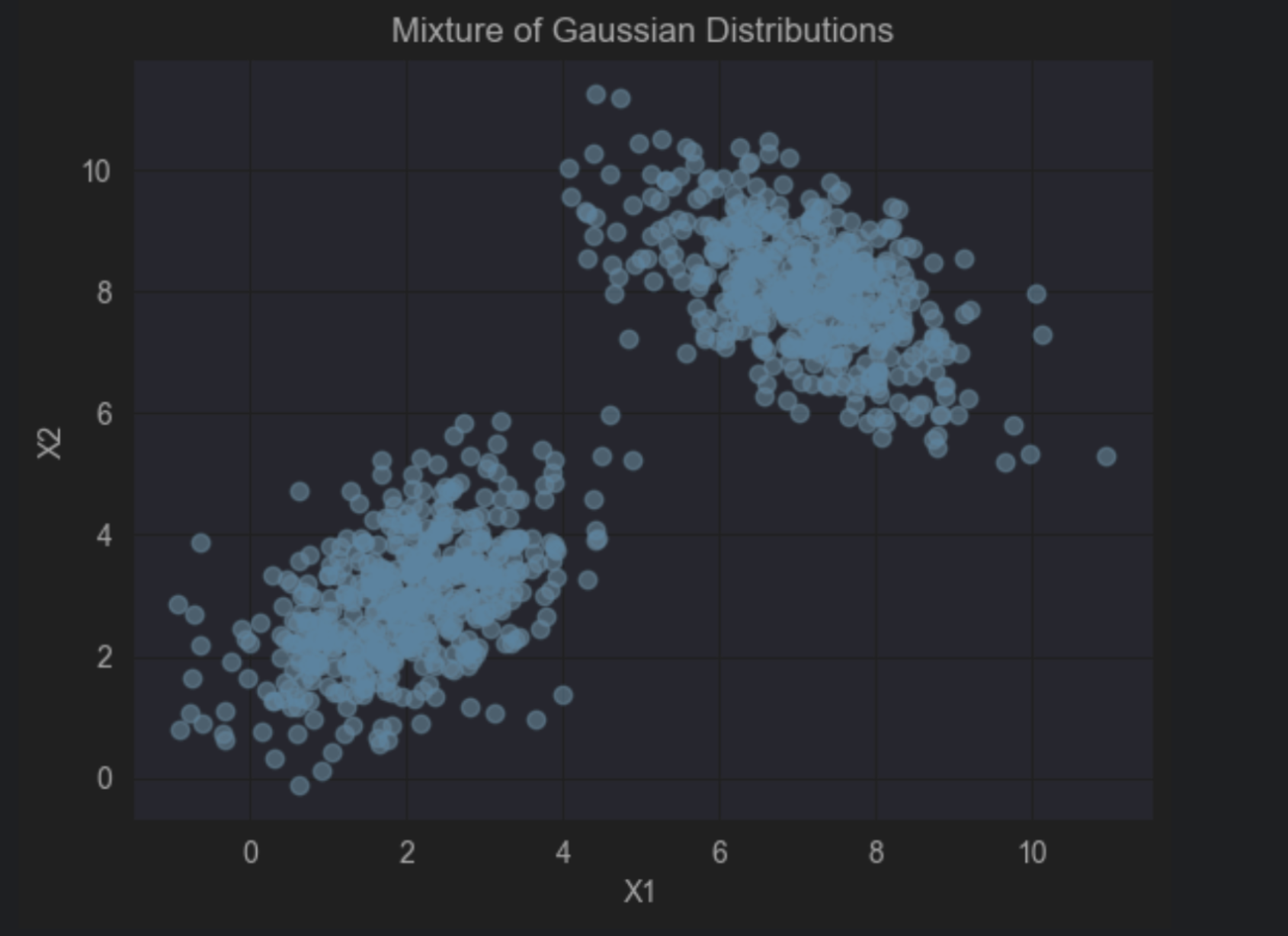
아래 코드를 실행하면 혼합 가우시안 분포가 생성됩니다. 즉 두 개 이상의 클러스터링이 생기기 때문에 전체 분포를 대표하는 샘플을 얻기 어렵습니다. 뿐만 아니라, 두개의 서로 다른 평균과 분산을 가지고 있어, 비선형적인 형태를 띄고 있습니다. 그리고 아래 코드는 이차원이지만, 차원수가 늘어나면 샘플을 효율적으로 샘플링하는게 더욱 어려워집니다.
import numpy as np
import matplotlib.pyplot as plt
# 두 개의 가우시안 분포의 파라미터 정의
mean1, cov1 = [2, 3], [[1, 0.5], [0.5, 1]]
mean2, cov2 = [7, 8], [[1, -0.5], [-0.5, 1]]
# 각 분포에서 500개의 샘플 생성
samples1 = np.random.multivariate_normal(mean1, cov1, 500)
samples2 = np.random.multivariate_normal(mean2, cov2, 500)
# 두 분포를 섞어서 혼합 가우시안 분포 생성
samples = np.vstack((samples1, samples2))
# 데이터 시각화
plt.scatter(samples[:, 0], samples[:, 1], alpha=0.6)
plt.title('Mixture of Gaussian Distributions')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
MCMC 방법은 마르코프 연쇄를 사용하여 목표 분포에서 샘플을 생성하는 방법으로, Gibbs Sampling과 Metropolis-Hastings Sampling은 이 방법의 대표적인 예입니다.
Gibbs Sampling
Gibbs Sampling은 조건부 분포를 사용하여 다차원 확률 분포에서 샘플을 생성하는 MCMC 방법입니다.
각 변수는 다른 변수들이 고정된 상태에서 조건부 분포로부터 샘플링됩니다.
장점
간단한 구현: 조건부 분포를 계산할 수 있다면 구현이 간단합니다.
효율적 샘플링: 다차원 공간에서 각 변수를 순차적으로 샘플링하여 효율적으로 샘플을 생성합니다.
단점
조건부 분포 계산의 어려움: 조건부 분포를 계산하기 어려운 경우 적용이 힘듭니다. 아래와 같은 가우시안 분포는 조건부 분포도 가우시안 분포가 되기 때문에 계산이 간단한 편이나, 베이즈 네트워크같이 변수간 의존성이 심해지면 점차 복잡해집니다. 뿐만 아니라 각 조건부 분포가 비선형함수를 띄면 난이도는 더욱 높아집니다.

Member discussion