Gradio
import tensorflow as tf
import numpy as np
import gradio as gr
# MNIST 데이터 로드
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 데이터 전처리
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
# 모델 정의
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
model = create_model()
# 학습 함수
def train_model():
class AccuracyCallback(tf.keras.callbacks.Callback):
def __init__(self):
self.accuracies = []
def on_epoch_end(self, epoch, logs=None):
self.accuracies.append(logs['accuracy'])
accuracy_callback = AccuracyCallback()
history = model.fit(x_train, y_train, epochs=3, validation_split=0.1, verbose=0,
callbacks=[accuracy_callback])
accuracy_text = "Training accuracies:\n"
for epoch, acc in enumerate(accuracy_callback.accuracies, 1):
accuracy_text += f"Epoch {epoch}: {acc:.4f}\n"
accuracy_text += f"\nFinal accuracy: {accuracy_callback.accuracies[-1]:.4f}"
return accuracy_text
# 예측 함수
def predict():
idx = np.random.randint(0, len(x_test))
image = x_test[idx]
true_label = y_test[idx]
prediction = model.predict(image[np.newaxis, ...])[0]
predicted_label = np.argmax(prediction)
display_image = (image.reshape(28, 28) * 255).astype(np.uint8)
return (f"Predicted: {predicted_label}, True: {true_label}", display_image)
# Gradio 인터페이스
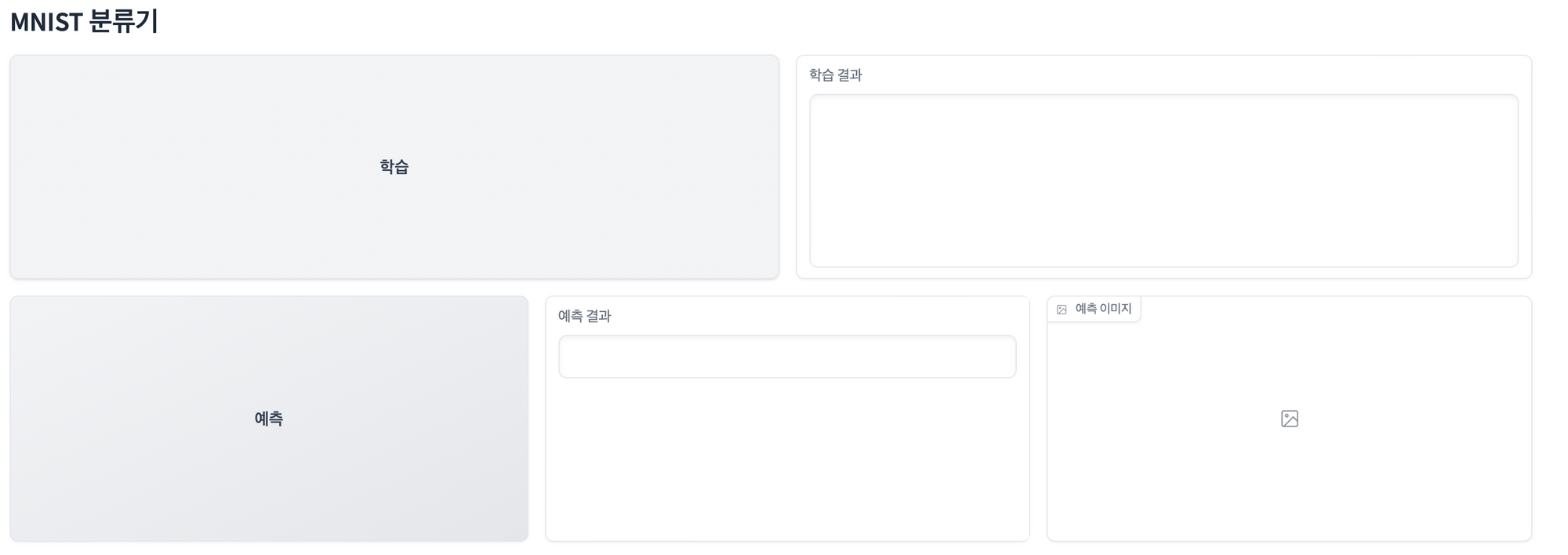
with gr.Blocks() as demo:
gr.Markdown("# MNIST 분류기")
with gr.Row():
train_button = gr.Button("학습")
output_text = gr.Textbox(label="학습 결과", lines=7)
with gr.Row():
predict_button = gr.Button("예측")
output_label = gr.Textbox(label="예측 결과")
output_image = gr.Image(label="예측 이미지")
train_button.click(train_model, outputs=output_text)
predict_button.click(predict, outputs=[output_label, output_image])
demo.launch()
Streamlit
import streamlit as st
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# MNIST 데이터 로드
@st.cache_resource
def load_data():
return tf.keras.datasets.mnist.load_data()
(x_train, y_train), (x_test, y_test) = load_data()
# 데이터 전처리
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
# 모델 정의
@st.cache_resource
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
model = create_model()
# 학습 함수
def train_model():
class AccuracyCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
accuracy = logs.get('accuracy')
st.session_state.accuracies.append(accuracy)
st.session_state.progress_bar.progress((epoch + 1) / 5)
st.session_state.status_text.text(f"Epoch {epoch + 1}/5 completed")
accuracy_callback = AccuracyCallback()
history = model.fit(x_train, y_train, epochs=5, validation_split=0.1, verbose=0,
callbacks=[accuracy_callback])
st.session_state.trained = True
# 예측 함수
def predict():
idx = np.random.randint(0, len(x_test))
image = x_test[idx]
true_label = y_test[idx]
prediction = model.predict(image[np.newaxis, ...])[0]
predicted_label = np.argmax(prediction)
return image, predicted_label, true_label
# Streamlit 앱
st.title("MNIST 분류기")
if 'trained' not in st.session_state:
st.session_state.trained = False
st.session_state.accuracies = []
col1, col2 = st.columns(2)
with col1:
if st.button("학습"):
st.session_state.accuracies = []
st.session_state.progress_bar = st.progress(0)
st.session_state.status_text = st.empty()
train_model()
st.session_state.progress_bar.empty()
st.session_state.status_text.empty()
accuracy_text = "Training accuracies:\n"
for epoch, acc in enumerate(st.session_state.accuracies, 1):
accuracy_text += f"Epoch {epoch}: {acc:.4f}\n"
accuracy_text += f"\nFinal accuracy: {st.session_state.accuracies[-1]:.4f}"
st.text_area("학습 결과", accuracy_text, height=200)
with col2:
if st.button("예측"):
if not st.session_state.trained:
st.warning("먼저 모델을 학습시켜주세요.")
else:
image, predicted_label, true_label = predict()
st.image(image.reshape(28, 28), caption=f"Predicted: {predicted_label}, True: {true_label}", width=200)
st.markdown("---")
st.markdown("학습 버튼을 눌러 모델을 학습시킨 후, 예측 버튼을 눌러 랜덤한 MNIST 이미지에 대한 예측을 확인하세요.")

- 학습시에는 Progess Bar로 진척도를 보여주다가 종료되면 Epoch별 Metric을 보여주었는데, 예측버튼 클릭시이 부분이 사라졌다

Member discussion