Transformer 요약 정리

- 강점
- Attention을 활용, 반복을 최소화하고, Positional Encoding을 활용해서 parallelization 지원
- Attention을 활용하여 Input Sequence에서 다른 Sequence의 어떠한 부분이 중요한지 결정
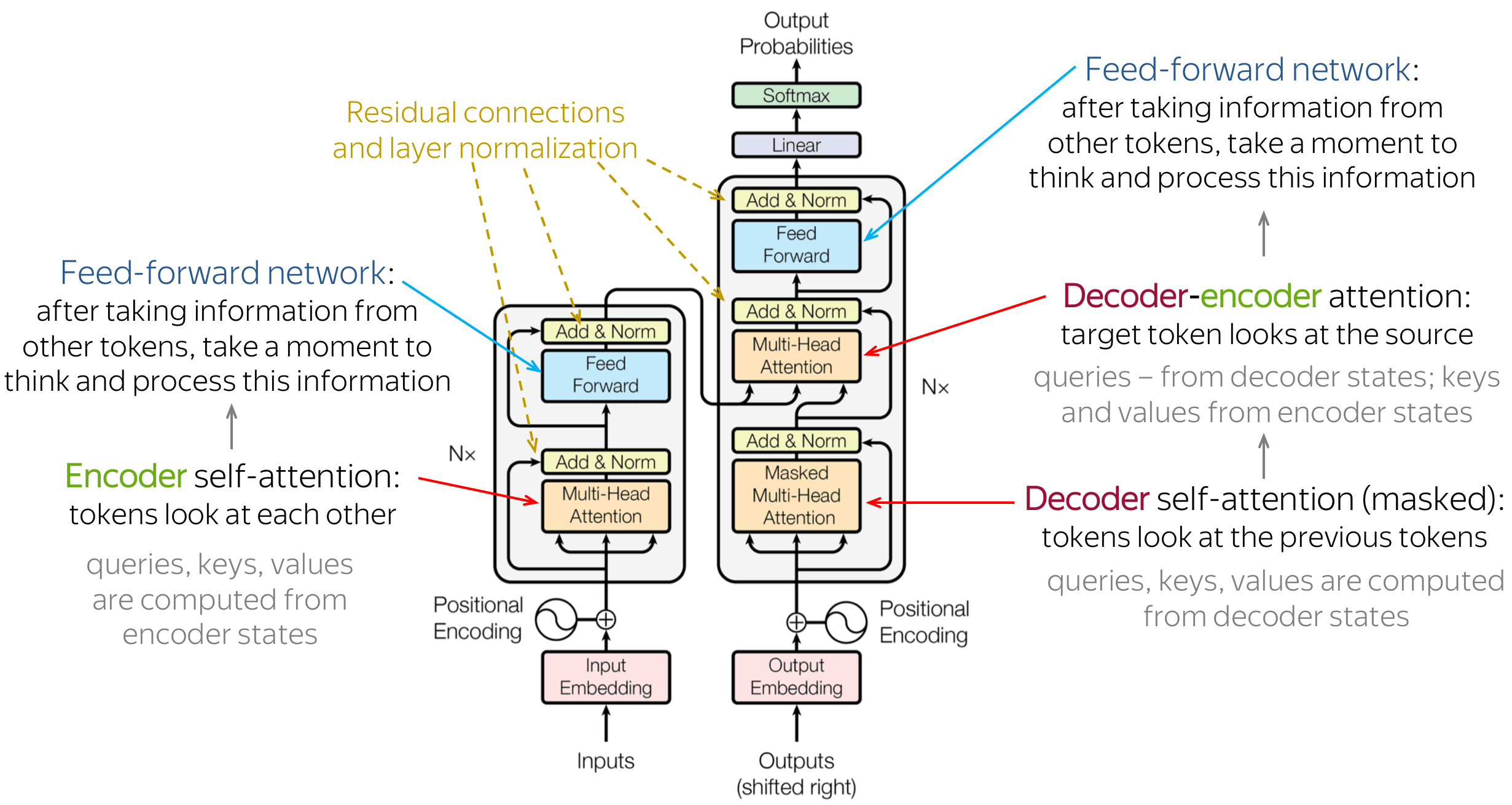
- 구조
- $X$개의 Encoder와 $X$의 Decoder로 구성되어 있음
- Encoder와 Decoder의 수는 동일하며, Encoder는 모두 동일한 구조, but Weight Matrix를 공유하지 않음
- Encoder는 Self-Attention과 Feed-Forward로 구성되어 있음
- Self Attention에서는 $K,Q,V$ Vector를 생성후 $Q$와 $K$의 내적으로 Attention Score를 계산후 $\sqrt{|K|}$로 나누어준 후 Softmax를 거쳐 $V$를 곱한 후 이걸 다 더 해서 Feed-Forward로 간다.
- 이 때 Multi Head Attention이라는 것은 $N$개의 Encoder를 거쳐 $N$개의 공간에 투영한 $K,Q,V$ Vector가 생긴다는 의미로 성능을 향상시키는 요소가 될 수 있다. 다양한 공간에서 Vecotr를 표현하기 때문이다.
- Feed-Forward는 Self Attention의 출력과 Positional Encoding이 결합되어 들어감.
- 이후에 Residual Connection, Layer Normalization 등을 거친다.
- $K, V$ Vector는 Encoder의 출력으로 가서 Decoder의 입력으로 간다.
- Decoder는 크게 두개 정도가 Encoder와 다르다. Masked self-attention layer와 Encoder-Decoder Attention이다.
- Masked Self Attention은 input과 달리 현재 입력 시퀀스 이전의 위치에 대해서만 Score를 계산한다. 문장을 왼쪽부터 오른쪽으로 변환한다고 할 때 사람의 관점에서 보면 이전의 위치만 아는게 맞기 때문이다. 오른에 대해서는 Softmax 변환전 $Inf$로 모두 처리하여 배제한다.
- Encoder-Decoder Attention은 Encoder의 출력에서 가지고 와서, Encoder 정보 기준에서 Attention Scoring을 한다.
- 이후에 FCN(Fully Connected Layer)로 연결하고, Softmax를 거쳐서 단어별 확률을 뽑아 가장 확률이 높은 단어로 조합을 하여 최종 출력으로 내보낸다.
Refernece
Member discussion