CNN, Convolution Neural Network 주요 개념
CNN은 Convolution Neural Network(이하)로서 합성곱을 적용한 신경망으로 신경망 중에서 가장 처음 배우는, 널리 알려진 신경망중 하나이다.
대략적인 구조는 아래와 같다. Convolution과 Pooling을 거듭하는 Feature Learning Layer와 배운 내용을 바탕으로 Classification을 진행하는 Classification Layer로 구성이 된다.

CNN이라는 이름이 의미하는 것처럼 이 Neural Network의 핵심아이디어는 Convolution으로 다음과 같은 방식으로 작동한다.
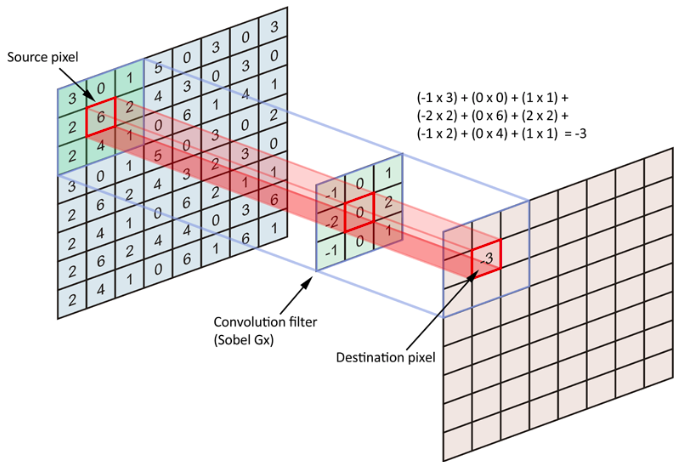
위 이미지에서 볼 수 있듯이 Kernel 또는 Filter를 거쳐서 만들어진 Output을 Feature Map이라고 한다. Actiation Map은 Input Image의 특정 패턴을 학습한 Output이다. FCL(Fully Connected Layer)가 Input Image의 모든 패턴을 학습하는 것과는 다른 부분이다. 그리고 Convolution Layer에서는 앞서 언급한 Filter를 천천히 전체 Space에 걸쳐서 순회하면서 Feature Map을 만드는데 이 때 움직이는 간격을 Stride라고 말한다. 아래 이미지는 Stride가 1인 경우를 도식화한 것이라고 불 수 있다.

Feature Map을 생성한 후 Activation Function까지 적용한 결과를 Activation Map이라고 하는데 당연하게도 Activation Map의 Size는 Input Image와 Size보다 작아지는데 이 때 적절한 열과 행을 추가해서 Size를 조절할 수 있다. 이 때 사용하는 것이 Padding이다. Padding을 통해 Input Image의 외곽을 포함한 패턴을 좀 더 잘 학습할 수 있게 된다 .
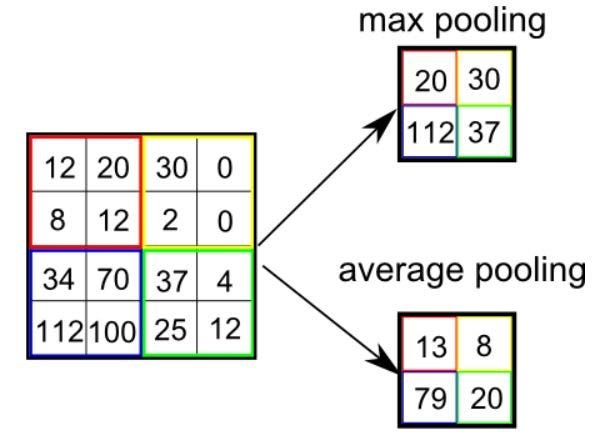
Stride를 통해서 우리는 Feature Map의 Size를 조절할 수 있다.(Down Sampling) 통상 Stride를 통한 Down Sampling보다는 책들은 Pooling을 통한 Down Sampling을 자세히 소개하는 것 같다. Neural Network는 상당히 많은 Parameter(Weight)를 필요로 하는데 Pooling은 이러한 Parameter의 수를 줄이고 나아가 Image에서 Convolution을 통해서 추출된 패턴에서 한 번 더 특정 패턴만을 추출할 수가 있다. 대표적인 방식으로는 Max/Min/Average Pooling이 있고 Max Pooling이 많이 사용된다. 아무래도 특정 Pattern의 존재여부를 통해 분류를 하는 것이 조금 더 높은 분류 정확도를 보여서 그런 듯하다.

참고1: CNN, Convolutional Neural Network 요약
참고2: A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way



Member discussion